class: center, middle, inverse, title-slide # Importieren von Daten --- class: center, middle 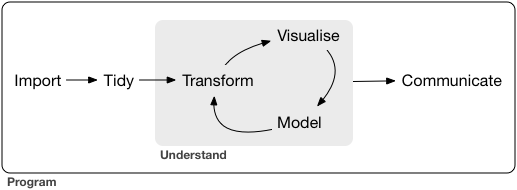 .small[Quelle: Wickham, H., & Grolemund, G. (2016). R for data science: import, tidy, transform, visualize, and model data." O'Reilly Media, Inc.] --- ## Einführung Bisher hatten Sie sich mit bestehenden Datensätzen in Form von R Objekten beschäftigt In den Projekten sind Dinge wichtig wie: - Zusammenfügen von Informationen aus verschiedenen Datenquellen - Bereinigen des Datensatzes (falsch ausgefüllte Fragebögen, Codierung von Zeitreihen in Datastream, ...) - Konsistenzchecks (Outlier, doppelte Beobachtungen, ...) .alert[Dies wollen wir nun lernen.] --- ## Daten einlesen - Es ist selten, dass Sie in ihrer Analyse auf bereits bearbeitete Datensätze stoßen - *Meistens:* Daten müssen aus Excel, Text, Datenbank, API, HTML ... importiert werden - Sie können sich Excel- und Textdateien aus den meisten Datenbanken generieren lassen (DAFNE, Datastream, Bloomberg ...) - Pakete `readr` and `readxl` können uns bei Excel und Textdateien helfen - Paket `rvest` kann uns bei HTMLs helfen - Paket `haven` kann uns bei anderen Formaten wie z.B. Stata-Dateien helfen --- ## Daten einlesen - Sie sollten Datensätze grundsätzlich _nicht_ in Excel abspeichern - Vorteil von ".csv" (comma-separated value) oder ".txt" (tab-separated value) Dateien: - Sie sind plattformunabhängig lesbar (UNIX/Windows/MAC) - Sie benötigen kein lizenziertes Programm um den Datensatz öffnen zu können - Der Datensatz wird im ASCII Format abgespeichert, wodurch er in jedem Texteditor begutachtet werden kann - Reproduzierbarkeit der Analysen durch Datengrundlage gegeben -- .instructions[Deshalb gilt: Datensätze bitte **immer** in ".csv" oder ".txt"-Format abspeichern!] .alert[**Außnahme:** Sie arbeiten nur mit anderen R-Nutzern zusammen, dann können die Daten in .Rds abgespeichert werden.] --- ## Daten einlesen Um Dateien einzulesen sollten Sie drei Dinge wissen: - Wo befinden Sie sich aktuell in ihrem System? - Aktuelles _Arbeitsverzeichnis_ mit `getwd` - Wo befindet sich die einzulesende Datei? - Pfad zur Datei mit `file.path` - Welches Format hat die Datei? - ".csv", ".txt", ".xls(x)", ".dta" ... --- ## Das Arbeitsverzeichnis - Wo befinden Sie sich aktuell und wie kann das _Arbeitsverzeichnis_ geändert werden ```r getwd() ``` .question[Laden Sie das Git-Repository mit den Vorlesungsunterlagen herunter. Anschließend wechseln Sie ihr Arbeitsverzeichnis in R zu dem Ordner `wrangling`.] Wechseln Sie in den Ordner `wrangling` mit Hilfe des Befehls `setwd()` ```r setwd("/Pfad/zum/neuen/Arbeitsverzeichnis") # Achten Sie auf die Anführungszeichen und Slashes! ``` -- ```r setwd("/home/rieber/datascience-teaching/2020/wrangling/") # Pfad bei UNIX setwd("C:/Users/rieber/Desktop/datascience-teaching/2020/wrangling/") # Pfad bei Windows setwd("/Users/rieber/Desktop/datascience-teaching/2020/wrangling/) # Pfad bei Mac #Check des Pfades getwd() ``` --- ## Beispieldatensätze herunterladen und einlesen .question[Welche Datensätze befinden sich in dem Unterordner _data_?] -- ```r list.files("data/") ``` ``` [1] "gapminder_life.rds" [2] "Geburtenrate-Beispieldatensatz.csv" [3] "Geburtenrate-Lebenserwartung_Beispiel.xlsx" [4] "Geburtenrate-Lebenserwartung.xlsx" [5] "Kindersterblichkeit.dta" [6] "Kindersterblichkeit.xlsx" ``` --- ## Spreadsheets einlesen - Ein Großteil aller Datensätze werden in Spreadsheets abgespeichert - Ein solches Spreadsheet ist im Grund eine Datei in Data Frame-Format <img src="figs/CSV-Beispiel.png" width="100%" style="display: block; margin: auto;" /> --- ## Spreadsheets einlesen - Enthält die Datei eine _Kopfzeile_ in der die Variablennamen definiert werden? - Datei sollte vor dem Einlesen betrachtet werden - Mit einem Editor - In RStudio direkt (Rechtsklick auf Datei -> Anschauen mit "Rstudio") - Einige Spreadsheet können nicht mit einem Texteditor geöffnet werden - z.B. Excel-Dateien - Dateiformat wird häufig verwendet - **keine** eigenen Datensätze darin abspeichern - _jedoch_ dazu in der Lage sein Excel-Dateien in R einzulesen (mit `readxl` Paket) --- layout: false class: center, middle name: readr # `readr` und `readxl` .pull-left[<center> <a href="https://readr.tidyverse.org"> <img src="figs/readr.png" style = "width: 200px;"/> </a> </center>] .pull-right[<center> <a href="https://readxl.tidyverse.org"> <img src="figs/readxl.png" style = "width: 200px;"/> </a> </center>] --- ## `readr` und `readxl` Mit den Paketen `readr` und `readxl` können verschiedene Datensätze eingelesen werden. Für alle Datensätze, welche mit einem Texteditor geöffnt werden können, das `readr` Paket: - read_table, read_csv, read_csv2, read_tsv, read_delim - Beim Einlesen erhalten Sie eine Nachricht, welcher Datentyp pro Spalte erkannt wurde - Funktionen aus dem Pakt `readr` sind deutlich schneller die build-in Funktionen von R - _Nicht benutzen:_ read.table, read.csv, read.delim ```r library(readr) geburtenrate <- read_csv("data/Geburtenrate-Beispieldatensatz.csv") ``` --- ## `readr` und `readxl` Für Excel Dateien gibt es das Paket `readxl` mit den Funktionen: - read_excel, read_xls, read_xlsx - Mit `excel_sheets` erfahren Sie welche Tabellenblätter die Datei beinhaltet - Hier können durch `sheet` einzelne Tabellenblätter angesprochen werden ```r library(readxl) excel_sheets("data/Geburtenrate-Lebenserwartung_Beispiel.xlsx") ``` ``` [1] "Lebenserwartung_Geburtenrate" "Erklärung" ``` ```r leben_und_geburt <- read_xlsx("data/Geburtenrate-Lebenserwartung_Beispiel.xlsx", sheet="Lebenserwartung_Geburtenrate") ``` --- ## `readr` und `readxl` Sowohl `readr` als auch `readxl` Datensätze werden als `tibble` (eine aktualisierte Form eines Data Frame) eingelesen .pull-left[ ```r geburtenrate %>% select(1:4) %>% head(4) ``` ``` # A tibble: 2 x 4 country `1950` `1951` `1952` <chr> <dbl> <dbl> <dbl> 1 Germany 2.07 2.08 2.11 2 South Korea 4.02 4.33 4.89 ``` ] .pull-right[ ```r leben_und_geburt %>% select(1:4) %>% head(4) ``` ``` # A tibble: 4 x 4 country `1950_life_expectancy` `1951_life_expectancy` `1952_life_expectancy` <chr> <chr> <chr> <chr> 1 Brazil 50.33 50.59 51.1 2 Canada 68.26 68.53 68.72 3 China 41.04 41.98 42.91 4 Germany 66.91 67.08 67.4 ``` ] --- ## Unterschied zwischen `readr`, `readxl` und Base R .pull-left[ **`readr` und `readxl`** - Die von `readr` eingelesenen Daten werde als `tibble` abgespeichert- - `readr` erkennt automatisch Faktorvariablen und kann String- und Faktorvariablen unterscheiden - Datum und Zeit wird durch das `readr` Paket direkt erkannt und in ein R Datum umgewandelt - Das Einlesen durch `readr` ist ~10 mal schneller als in den Basisfunktionen ] .pull-right[ **Base R** - Die Basisfunktionen (read.csv, read.table oder read.delim) speichern die Daten als Data Frame - Die Basisfunktionen lesen String-Variablen als Faktorvariablen ein - Datum und Zeit werden nicht erkannt und müssen manuell umgeformt werden ] --- ## Das `haven` Paket - Neben Excel und R wird in der Wirtschaft und Wissenschaft oft Stata, SPSS und SAS eingesetzt - Durch das `haven` Paket können auch diese Datensätze eingelesen werden - Das `haven` Paket bringt Flexibilität, denn hierdurch können Sie: - mit Personen kooperieren, welche Stata verwenden - Stata-Datensätze einlesen, welche oft mit Artikeln in Fachzeitschriften veröffentlicht werden ```r library(haven) kindersterblichkeit <- read_dta("data/Kindersterblichkeit.dta") head(kindersterblichkeit,4) ``` -- ``` # A tibble: 4 x 3 Country Year Mortality <chr> <dbl> <dbl> 1 Afghanistan 1950 435. 2 Afghanistan 1951 432. 3 Afghanistan 1957 376. 4 Afghanistan 1958 370. ``` --- ## Probleme beim Einlesen von Daten Wenn Sie Daten in R einlesen kann einiges schief gehen. Hier einige Beispiele: - Datensätze können mehrere Kopfzeilen enthalten - Datensätze können in einem ungünstigen Format abgespeichert sein - Zellen können leer sein - Die Kodierung kann anders sein als erwartet - Bzgl. der Kodierung, insbesonder im Hinblick auf Unicode ist [dieser Blogeintrag](https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/) sehr interessant